
In recent years, Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have been widely used for tasks like image recognition, sequence prediction, and natural language processing. However, as the complexity of tasks increases, there has been a need for more advanced architectures that leverage the strengths of both CNNs and RNNs. This led to the emergence of Cascade Convolutional Recurrent Neural Networks (CC-RNNs) and Parallel Convolutional Recurrent Neural Networks (PC-RNNs). These architectures offer more robust learning capabilities, by combining the spatial feature extraction ability of CNNs with the temporal sequence modeling strength of RNNs, all in unique structures.

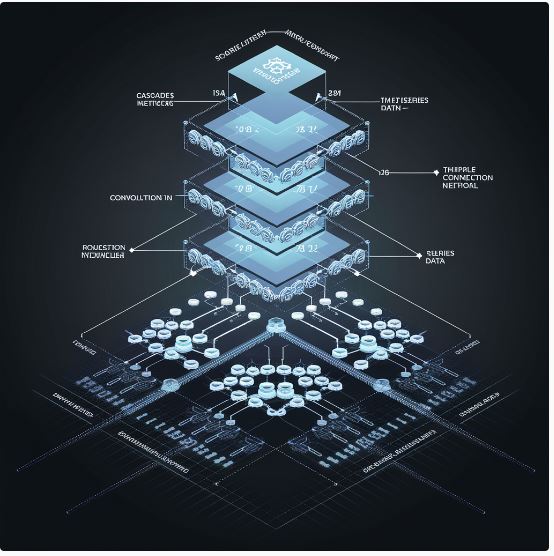
What Are Cascade and Parallel Convolutional Recurrent Neural Networks?
Cascade Convolutional Recurrent Neural Networks (CC-RNNs) refer to an architecture where the CNN and RNN are sequentially connected. Typically, the CNN component processes raw input data, such as images or sequential text, extracting hierarchical spatial features. The output from the CNN is then passed into an RNN, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), to capture temporal dependencies or sequential patterns in the features extracted by the CNN. This model excels at tasks requiring both spatial and temporal understanding, such as video processing, speech recognition, and time-series forecasting.
Parallel Convolutional Recurrent Neural Networks (PC-RNNs), on the other hand, process the data through both CNN and RNN networks simultaneously. In this configuration, the CNN focuses on the spatial aspects while the RNN focuses on the temporal sequence in parallel. At the end of each branch, their outputs are concatenated or merged before feeding into the final decision layer. This architecture allows for more efficient feature fusion, enabling the model to handle multi-dimensional data more effectively, particularly when both spatial and temporal information are equally important.
Key Differences Between Cascade and Parallel Convolutional RNNs
- Architecture:
- Cascade: CNN followed by an RNN. The input passes through the CNN first before being processed by the RNN.
- Parallel: The CNN and RNN work concurrently on the input, and their outputs are merged at the final stage.
- Advantages:
- Cascade Architecture: Effective for tasks where spatial features are critical before temporal dependencies. This structure is advantageous for hierarchical tasks, such as image-captioning.
- Parallel Architecture: Efficient for tasks requiring equal attention to spatial and temporal aspects. It’s more scalable to complex datasets with multidimensional inputs, such as video classification.
- Flexibility:
- Cascade: Easier to implement with predefined pipelines of feature extraction and sequence prediction.
- Parallel: More flexible but requires efficient fusion methods for combining CNN and RNN outputs without information loss.
Real-World Applications
- Speech Recognition: In speech recognition tasks, Cascade CRNNs are typically used. CNNs extract the spectral features from audio signals, and RNNs capture the temporal sequence of speech sounds.
- Video Classification: Parallel CRNNs are ideal for tasks like video classification, where both spatial (frame-based features) and temporal (sequence of frames) information are essential for predicting the correct label.
- Time-Series Forecasting: In tasks such as financial data prediction or weather forecasting, Cascade CRNNs are useful as they prioritize the extraction of key features over time-series data and apply the RNN to model temporal dependencies.
- Natural Language Processing: Cascade models can be used for text-based tasks, where CNNs capture the structural features of sentences, and RNNs are used to understand the sequential nature of language.
Advantages of Cascade and Parallel Convolutional Recurrent Networks
- Improved Feature Learning: By combining CNNs and RNNs, these models learn rich representations of data, capturing both spatial and temporal information, which is essential in multimedia tasks like video processing and audio recognition.
- Flexibility in Modeling: The parallel structure provides flexibility to handle multi-dimensional datasets. It efficiently integrates spatial and sequential dependencies, enabling better performance on tasks where both are critical.
- Scalability: With parallel processing, these networks can scale to larger datasets and complex tasks, particularly when the task requires significant computation of spatial and temporal features.
How to Implement Cascade and Parallel Convolutional RNNs
Cascade CNN-RNN Implementation (Example with TensorFlow/Keras):
pythonCopy codefrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, LSTM, Dense, Flatten
# Building a Cascade CNN-RNN Model
model = Sequential()
# CNN Layers
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# RNN Layer
model.add(LSTM(100, return_sequences=False))
# Fully Connected Layer
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Parallel CNN-RNN Implementation (Example with PyTorch):
pythonCopy codeimport torch
import torch.nn as nn
import torch.nn.functional as F
class ParallelCNNRNN(nn.Module):
def __init__(self):
super(ParallelCNNRNN, self).__init__()
# CNN Layers
self.conv1 = nn.Conv2d(3, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.fc1 = nn.Linear(64*6*6, 128)
# RNN Layer
self.rnn = nn.LSTM(128, 100, batch_first=True)
# Fully Connected Layer
self.fc2 = nn.Linear(100, 10)
def forward(self, x, seq_input):
# CNN Path
x = F.relu(self.conv1(x))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, 64 * 6 * 6)
x = F.relu(self.fc1(x))
# RNN Path
seq_output, _ = self.rnn(seq_input)
# Merge CNN and RNN outputs
merged = torch.cat((x, seq_output[:, -1, :]), dim=1)
output = self.fc2(merged)
return output
Final Thoughts
Cascade and Parallel Convolutional Recurrent Neural Networks offer robust solutions for complex machine learning tasks that involve both spatial and temporal dependencies. By leveraging the strengths of CNNs and RNNs in structured or parallel configurations, these models can provide superior performance on tasks such as speech recognition, video classification, and time-series forecasting. Understanding when to use each architecture is key to designing efficient and scalable models.
Optional Reading:
- Explore advanced fusion techniques for CNN-RNN architectures.
- Study hybrid deep learning models combining CNNs, RNNs, and attention mechanisms.
- Learn about Transformer models as alternatives to RNNs in sequential tasks.
By diving deeper into these models, you can gain valuable insights into their performance, applications, and implementation strategies.